邊緣 AI 是 IC 設計現在創新最蓬勃發展的領域。以下重點摘譯 IMEC 的邊緣 AI 報告分享讀者。
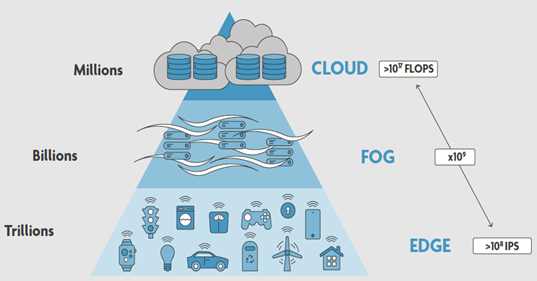
因為大多數 AI 任務無法高效率地在傳統處理器 (例如 CPU 和常規 GPU) 上執行,高複雜性、高效率、低功耗與處理大量數據集的需求催生了針對特定 AI 任務進行優化的新一代計算機體系結構。這些新體系結構的處理器目前較為大眾所熟知的是神經網路處理器 (NPU,Neural Processing Units) 和張量處理器 (TPU,Tensor Processing Units)。
NPU 與 TPU 以專用加速器、獨立處理器或是對現有處理器結構加以修改 (例如,添加張量核 (Tensor Cores) 的 GPU) 等形式,對傳統 CPU 和 GPU 進行補強。因此,專注於 AI 的晶片組市場呈現爆炸性成長。以往絕大多數 AI 應用程式和服務都是基於雲端,因此對 AI 硬體的大部分投資都集中在雲端智慧和大數據上,但另一項技術發展 — 邊緣 AI (Edge AI) — 開始受到矚目,並且正迅速蓬勃發展。
為什麼要關注邊緣 AI?
- 邊緣 AI 的受到矚目主要是由各類型行動服務 (4G/5G/Wi-Fi..)、物聯網 (IoT)、可穿戴裝置和工業互聯網等應用的爆炸性成長所推動。此外,通信成本、延遲、安全性、隱私和電源效率等因素也推升了需要增加本地運算和 AI 驅動處理功能的需求。
- 邊緣 AI 讓推理 (Inference) 甚至特定學習功能可以被部署在資源受限的裝置 (例如智慧型手機、物聯網設備、智慧可穿戴裝置、智慧家庭和自動駕駛汽車等..) 的感測器 (Sensors) 和執行器 (Actuators) 附近。
- 此外,需要即時決策的應用程式 (例如自動駕駛或醫療保健等),往返雲端造成的延遲將不切實際,因此需要邊緣 AI 來快速執行推理及執行。
雲端 AI 與邊緣 AI 的差異
- 大多數雲端應用程式專注於處理和解釋大型數據集,因此數據儲存頻寬和運算性能至關重要。而邊緣裝置因尺寸和電源等方面的限制,以現有通信技術,要將海量數據從邊緣裝置傳輸到雲端將會無法持續,並且效能會非常低,甚至帶來額外的安全風險。
- 邊緣 AI 早期實現大多數集中在數據分析和分類,或是事件/異常檢測 (通常與雲端協作) 上,然而趨勢是自主性和閉環反饋需求的不斷增加。在這種情況下,數據分析的結果用作控制器的輸入,並在非常短暫的時間內以具體且立即的行動進行轉換及執行任務。
- 在自主移動設備 (自駕車、無人機)、機器人、人機界面 (如 AR / VR)、腦機介面和可穿戴醫療裝置之類需即時反應的應用中,除了輸入 (感測器) 和輸出 (執行器) 模式外,這些系統還需要結合理解、推理和決策,因此具備本地運算能力的邊緣 AI 是必要的,需求也已經大幅增加。
- 綜合上述多種因素,實現邊緣 AI 最終會使用的運算模型、優化方法、系統架構、以及最終的系統整合和電路技術,將會與雲端 AI 完全不同。
邊緣 AI 的技術機會
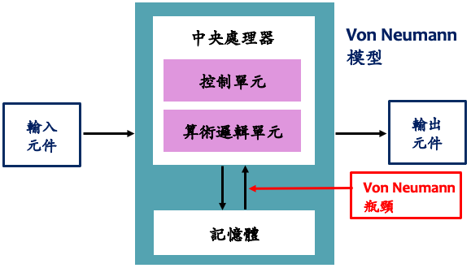
AI 功能在許多重要方面與 Von Neumann 模型所啟發的傳統演算法不同。因此實現需求的方法也會不同。一些主要區別:
- 基於學習的模型 vs. 儲存程式的模型;
- 長期和短期記憶的角色;
- 邏輯和記憶體的交織或分離;
- 互連的密度和拓撲結構;
- 以及計算的統計性質等。
在體積、功耗和實施成本都很關鍵的邊緣 AI,以上差异更爲明顯,計算功能與系統結構之間的匹配也更爲重要。下面介紹可能會産生最大影響的發展。
下面將介紹一些我們認可能會產生最大的影響的發展。
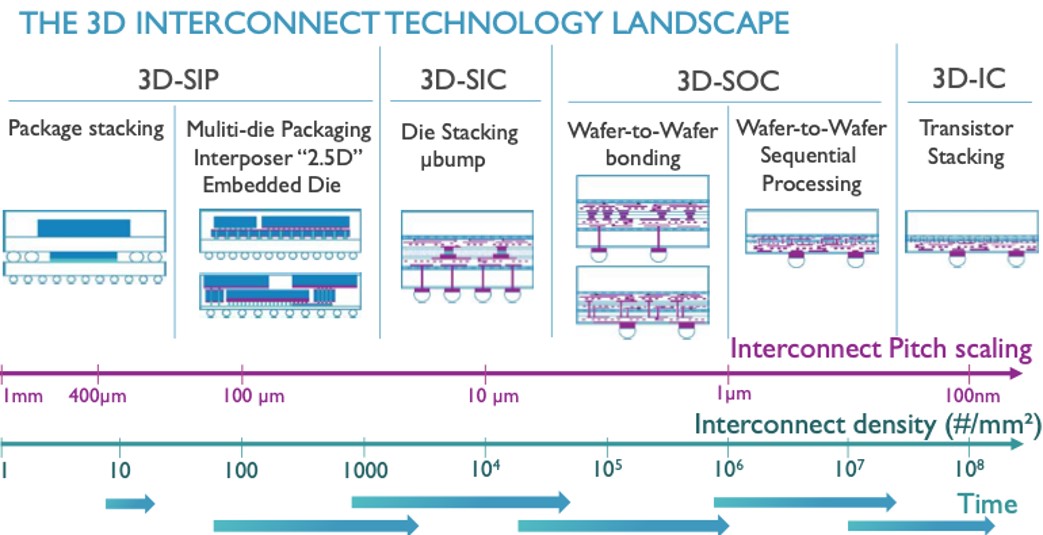
邊緣 AI 的技術機會 — 3D 整合(Integration)
3D 整合是對邊緣 AI的效率和占用空間産生重大影響的最大技術創新之一。3D 整合將記憶體堆叠在支援密集垂直連接的邏輯晶粒上,這提供了廣泛的介面通道和低延遲,大幅提升 AI 晶片效能。
除了邏輯記憶體整合,3D 整合還可以實現以前極難完成的互連拓撲。滿足一些神經形態結構的高扇入 (Fan-in) 需求。此外,3D整合也能影響感測與計算之間的介面,這對于許多 Edge應用程式也相當重要。
3D 整合技術也爲傳統 CMOS 製程中極難實現的選項打開了大門。例如,考慮動態可重新配置互連的可能性,將具有高關斷電阻 (Roff) 和低導通電阻 (Ron) 的高品質裝置嵌入到互連結構中。這些開關可以由緊挨其後或直接位于其上方或下方的非揮發性記憶體控制。
3D 互連技術的發展趨勢:
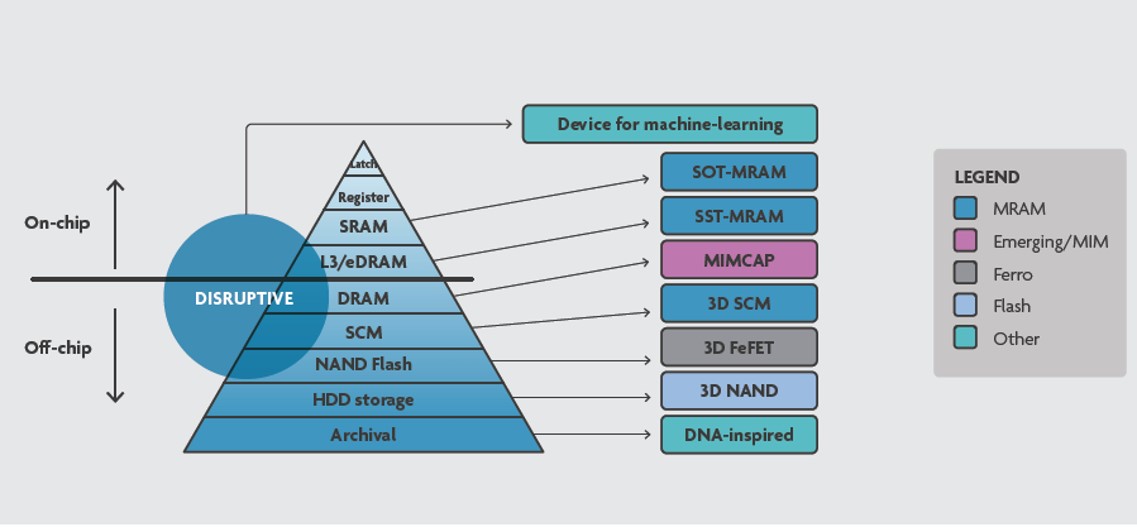
邊緣 AI 的技術機會 — 存儲器(Memory)
存儲器在 AI 扮演著核心角色,它與基于 Von Neuman 的傳統指令集處理器領域所熟悉的存儲器角色和需求相去甚遠。在那裏,存儲器訪問主要由不規則模式進行的指令和數據的獲取和儲存來控制。在深度學習網絡領域,存儲器的主要作用是獲取以高度規則模式構建的大量權重和數據,幷使這些數據流同步。
許多 AI 體系結構都受益于甚至需要分布式 – 高帶寬 – 低延遲訪問,這意味著需要重新考慮存儲控制器及重新組織存儲器架構和拓撲。在一些 AI 應用,例如自駕車,需要大量靠近處理器的可用數據集,因此存儲器密度相對重要。這可以由前面所討論過的 3D 集成技術來解决。
目前 AI 存儲器的主流仍是 DRAM,但根據不同的 AI 方法和實施策略,一些可能會變得有吸引力:
- 非易失性存儲器 (Non-Volatile Memory) 可能會成爲最突出的功能之一,非易失性及低漏電量是其主要吸引力。尤其是對于位于邊緣,始終處于連綫狀態系統的准靜態可重配置結構,該結構大多數時間是被讀取,僅偶爾被重寫。非易失性存儲器除了 3D NAND,還有新型的 MRAM、FeRAM等。
- 內存內計算 (In-memory-computing, IMC) 讓諸如矩陣乘法、關聯搜索和查找表等功能被分布在整個存儲器中 (可以是 SRAM 或任何類型的非易失性內存) 。其主要優點是减少數據的移動,因爲數據及計算都在存儲器內。其實現方式是使用非易失性存儲器儲存權重,以進行模擬分布式計算。
存儲器縱觀:
邊緣 AI 的技術機會 — 邏輯 (Logic)
今日提倡的大多數 AI 硬件加速器都集中在有效實現神經元功能的“某些”抽像上。已經有許多實現神經元功能的方法,包括數字神經處理器、大型陣列向量乘法器(Large Array-Vector Multiplier)、內存內計算(In-Memory Computing)、模擬乘法(Analog Multiplication)、憶阻器( Memristors) 等被提出。
神經元幷非尋找有效邊緣 AI 應追求的唯一邏輯元素,其它受到關注的還包括憶阻器(Memristors)、類突觸裝置(synapse-like devices)、非綫性振蕩器網路 (模擬和數字)、可調延遲綫 (Tunable Delay Lines) 等。
邊緣設備的一種可能的抽象化 (Abstraction) 是將其視爲智能的傳感/執行系統,此抽象化適用于 IoT、AR / VR設備、自主移動實體 (自駕車或無人機等)、以及可穿戴和可植入等設備。從這個角度來看,傳感及其相關計算可以被認爲是共生的。
這種以傳感器爲中心的觀點通常稱爲“傳感器內計算”。自然界中的一個明顯示例是視網膜,其神經元在通過視神經傳送資訊之前已執行各種形式的特徵提取。其他一些感官,如嗅覺系統,也是類似。
大多數傳感器實現所需要的技術與用于信號采集和計算的 CMOS 技術大不相同,因此,二種技術的集成是許多進行中研究的主題。
邊緣 AI 的技術機會 — 支援硬体的安全性
邊緣 AI 的最主要挑戰之一是確保安全性和隱私性,尤其許多應用程序如果被惡意利用,將會造成重大損失甚至危害生命安全。
受能耗限制的邊緣 AI 設備要求解决方案提供基于硬件的安全機制,例如唯一且不可更改的識別碼、身份驗證技術、位置感知等。這些安全機制與機器學習功能模塊緊密結合,讓兩種功能都能以最小的資源成本 (面積、功耗、存儲器…) 共同發揮作用。
雖然安全性通常出現在 AI 項目列表的最下面。但就重要性而言,它應該與效能和成本等要項相提幷論。一些先進加密技術正在研發,例如同態加密(Homomorphic Encryption) 所使用的計算模型類似于用于高維表示的機器學習系統。
參考來源:AI at the edge – a roadmap, IMEC